I run FF-16 on notepad.exe from Windows, twice with different parameters.
With the -cpf 40 parameter, the result of the run is shown on the left side of the image.
With the -cpf 40 -z 2 parameter, the result of the run is shown on the right side of the image.
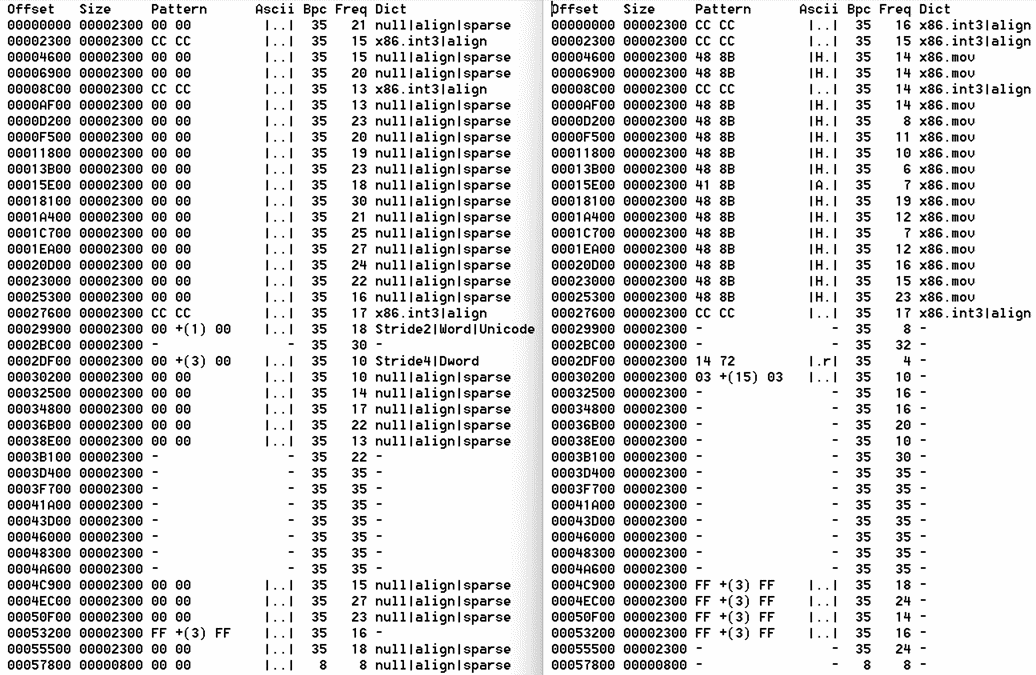
CPF stands for Chunks Per File. -cpf 40 requests that the analysis result to be summarized into 40 chunks (i.e., 40 lines). The reason for requesting a specific chunk size is to control the length of the output. It trades detail for compactness.
The -z 2 parameter runs a filter to remove 00 patterns. 00 bytes are ubiquitous in binary files. They can reveal the length of structures, but they also contribute to noise. In the left analysis, many 00 patterns are present, and I wanted to see whether more meaningful frequent patterns could be uncovered.
A quick side-by-side comparison of the two outputs shows that meaningful patterns appear in both analyses, so I decided to create a merged output that contains the meaningful patterns from both results.
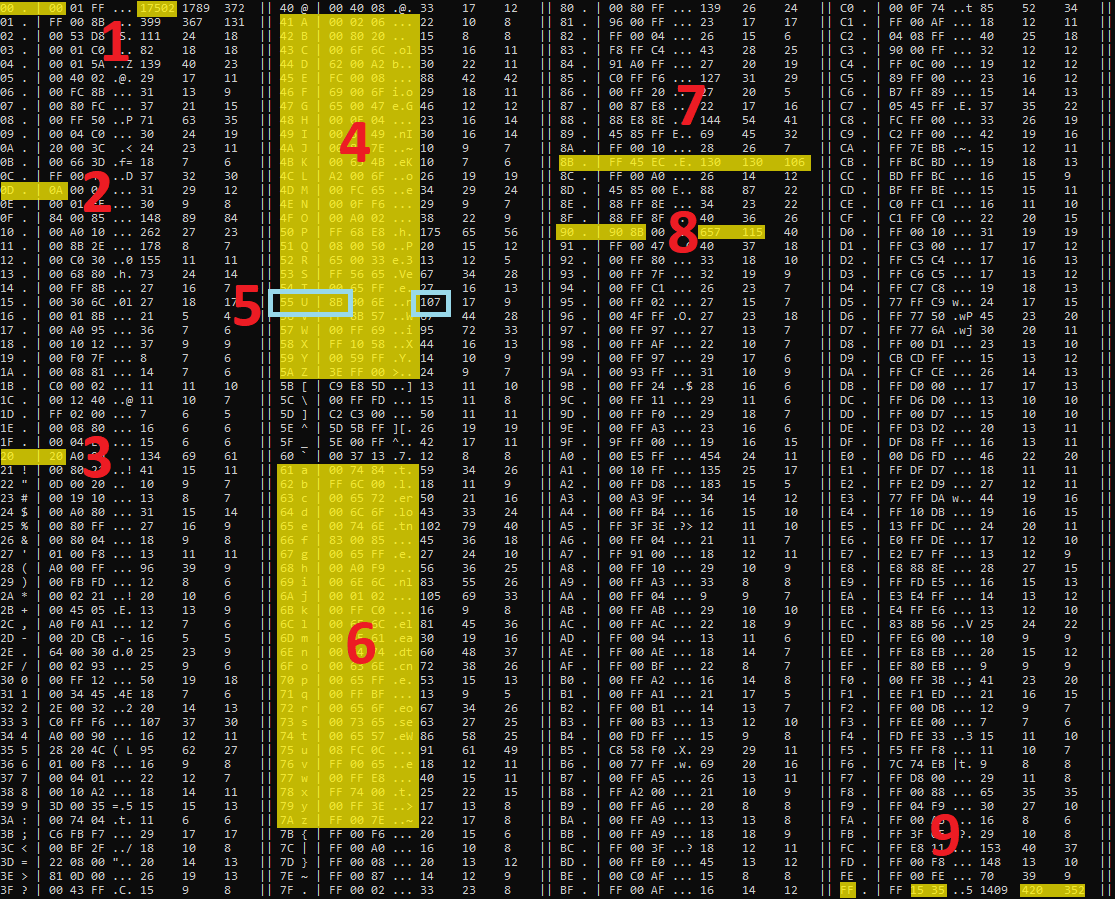
Below is the result of the merge.
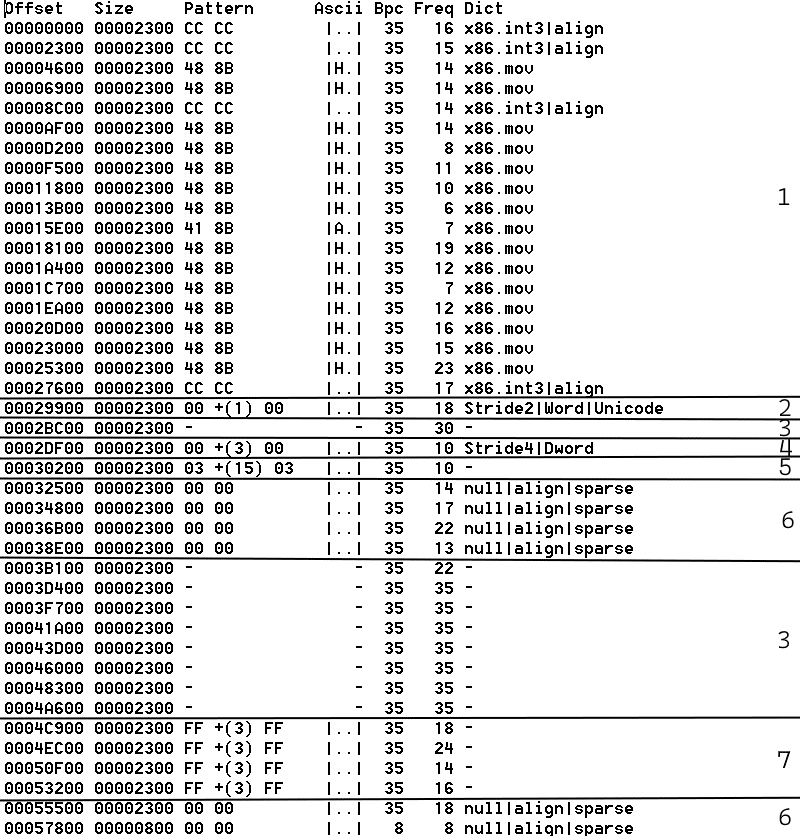
From the merge, seven different layouts can be identified.
Layout 1: Patterns resembling x86 mov / int 3 instructions.
Layout 2: In chunk 00029900, patterns of 00 ?? 00 suggest a sequence of 16-bit values.
The blocks from chunk 00029900 are listed below. When not using the -cpf parameter, FF-16 by default displays block-level results.
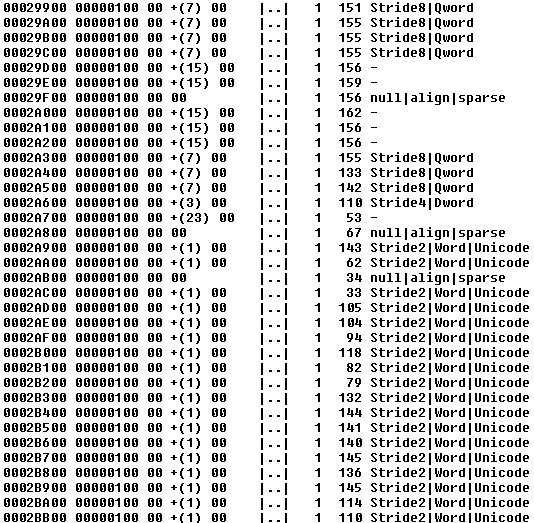
Below is a dump of the block at the first occurrence of 00 +(1) 00 in the chunk of 0002A900.
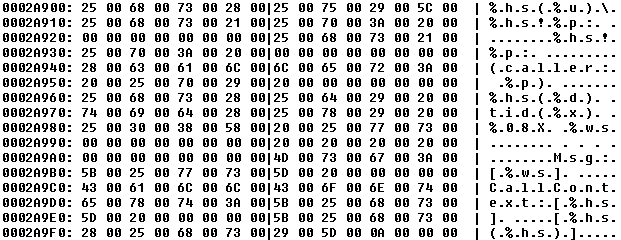
Now the dump confirms the presence of UTF-16 strings.
Layout 3: The - in the Pattern column indicates that no statistically significant pattern was found. It suggests random, encrypted, or compressed data.
Layout 4: The chunk summary indicates that a sequence of DWord values with byte 00 dominates.
Layout 5: The chunk summary indicates that a sequence of 16-byte structures dominates.
Layout 6: The chunk summary indicates that consecutive zero bytes dominate.
Layout 7: The chunk summary indicates that a sequence of DWord values with byte FF dominates.
References
- Analysis summarizing results into chunks using
-cpf 40parameter: ff-16_-cpf_40_notepad_20-Jun-2026.log - Analysis filtering out zero bytes and summarizing results into chunks using
-cpf 40 -z 2parameter: ff-16_-cpf_40_-z_2_notepad_20-Jun-2026.log - Analysis listing results for all blocks (no parameter): ff-16_notepad_20-Jun-2026.log
- FF-16: Snapshot
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}